
Cloud Crash: How AWS’s US‑EAST‑1 Glitch Rippled Across the Globe
Cloud Crash: On Monday, 20 October 2025, the global digital ecosystem jolted when Amazon Web Services (AWS) reported a major outage in its US‑EAST‑1 region (Northern Virginia). Networks, applications and cloud services spanning continents saw increased error‑rates, slow‑downs and partial or complete outages.
Incident Overview
Timeline of events
- Early hours (≈ 03:00 ET): Reports begin of widespread issues in US‑EAST‑1 region.
- Mid‑morning: AWS acknowledges “increased error rates and latencies” across multiple services.
- Late afternoon: Company reports all services restored by ~18:01 ET.
- Following hours: Continued back‑log clearance, residual performance issues and customer impact analysis.
Root cause & service effects
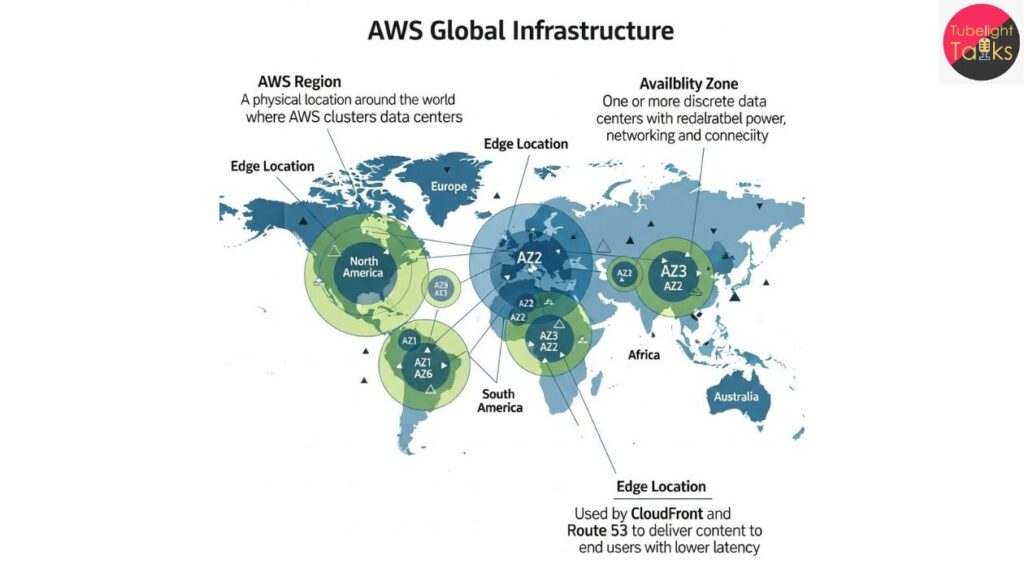
The disruption stemmed from a DNS (Domain Name System) failure tied to AWS’s DynamoDB API within the US‑EAST‑1 region. The DNS failure cascaded through AWS infrastructure, affecting over 140 services and triggering broad platform outages from consumer to enterprise‑scale.
What was impacted?
Popular apps and services including Snapchat, Fortnite, Amazon Alexa, Ring security cameras, Zoom, Slack and Venmo were disrupted globally. Financial services and airlines also reported interruptions in their user‑login, booking and payment systems.
Why this shook the internet
Centralised cloud dependency
AWS is estimated to power up to ~30 % of global cloud infrastructure, making an outage in a core region like US‑EAST‑1 disproportionately impactful.
Domino effect inside cloud systems
Even though the initial fault was specific to DNS, internal dependencies within AWS caused ripple‑effects: features like EC2 instance launches, Lambda invocation, and application‑certifications were delayed and degraded.
Global business and social disruption
For many users, everyday services — texting, streaming, online banking, home‑security apps — simply stopped working. This incident renewed questions about cloud resiliency, vendor lock‑in and digital risk management.
Broader implications
For enterprise IT & cloud strategy
Businesses reliant on single cloud‑domains may re‑evaluate their risk. Multi‑cloud or hybrid‑cloud resiliency strategies will gain traction.

For internet infrastructure‑governance
The event demonstrates how infrastructure failures in one region can have outsized global effects, raising concerns over digital sovereignty and concentration of risk.
For consumers & society
Even though this was not a cyber‑attack, users faced interruptions to services they trust — sparking discussions about accountability, transparency and the human reliance on global cloud firms.
Read Also: Global Media and Information Literacy Week
Spiritual Reflection on Digital Resilience
In a world racing toward technical sophistication, the teachings of Sant Rampal Ji Maharaj remind us of a deeper dimension. When the infrastructure backing our lives falters, it shows that true stability lies not in machines alone but in values, service, and interconnected responsibility. As cloud‑giants power our digital world, this incident prompts a reflection: technology without mindful use is brittle; innovation must be anchored in purpose, ethics and shared welfare.
What to watch next
Post‑Event Summary & Accountability
AWS has committed to publishing a Post‑Event Summary as per its own policy for major service‑events. Analysts will scrutinise what changes AWS initiates to prevent recurrence.
Shifts in cloud‑architecture
Expect push for regional diversity in cloud deployment, better fail‑over planning and increased multi‑cloud adoption.
Regulatory & business ramifications
Regulators may examine the systemic risk posed by dominant cloud‑providers. Businesses will adjust SLAs (service‑level‑agreements), insurance coverage and resilience‑budgets accordingly.
FAQs: AWS Outage 20 October 2025
Q1. What triggered the AWS outage?
AWS attributed the outage to a DNS‐resolution error affecting its DynamoDB API and EC2 internal network within the US‑EAST‑1 region.
Q2. How many services and users were impacted?
Over 1 000 services were affected globally. Thousands of platforms and millions of users across financial, consumer, enterprise and government sectors experienced disruptions.
Q3. Was this caused by a cyber‑attack?
No. Security experts confirm this was not a malicious incident but a technical failure. “It’s usually human error,” said Bryson Bort, CEO of cybersecurity firm Scythe.
Q4. What kinds of apps were down?
Apps including Snapchat, Fortnite, Venmo, Zoom, Ring, Slack, and Amazon’s Alexa ecosystem saw outages or degraded performance.
Q5. What should businesses learn from this?
Diversify cloud architecture, avoid single‑region dependencies (even within same provider), ensure robust disaster‑recovery plans and revisit SLAs with vendors.
Related Stories









Discussion (0)